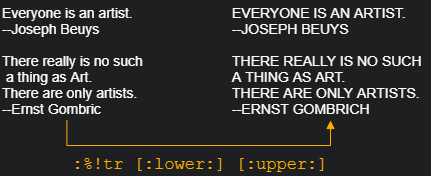
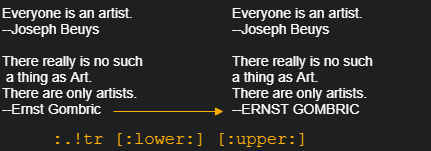
()用于保证需要作为整体而组合出现的字符。例如表达式a\(XY\)*b将会匹配ab, aXYb, aXYXYb, aXYXYXYb。
逆向引用(Back Reference)表达式\n,用于引用之前定义的第n个捕获组。其中n为数字1–9。
例如对于文本“he fly fly flies”,表达式\(fly\) \1将匹配“fly fly”。因为\1再次引用了第一个捕获组“fly”,所以将匹配2个“fly”。
捕获组匹配
| 示例 | 格式 | ||||||
|---|---|---|---|---|---|---|---|
| (800)555-1212 | ( | 3位数字 | ) | 3位数字 | - | 4位数字 | |
| (800) 555-1212 | ( | 3位数字 | ) | □ | 3位数字 | - | 4位数字 |
| (800)-555-1212 | ( | 3位数字 | ) | - | 3位数字 | - | 4位数字 |
| 800-555-1212 | 3位数字 | - | 3位数字 | - | 4位数字 | ||
| 555-1212 | 3位数字 | - | 4位数字 | ||||
假设需要查找以上多种格式的电话号码,其中:
- 可能包含区号,也可能没有区号;
- 区号由3位数字组成;
- 区号可能被括号包围,也可能没有括号;
- 区号和号码之间,可能有横线或者空格相连,也可能没有任何连接符;
- 号码由3位数字,横线连接符,和4位数字组成。
使用以下命令,可以满足以上格式需求:
/\((\d\{3})[- ]\?\|\d\{3}-\)\?\d\{3}-\d\{4}
我们将在下表中按照命令中的色彩标识,来分步理解命令中的表达式:
| 颜色 | 表达式 | 作用 |
|---|---|---|
| 红 | \( to \) | 匹配区号及其后的连接符的捕获组 |
| 青 | \? | 匹配0个或1个捕获组(即区号部分) |
| 紫 | \d\{3}-\d\{4} | 匹配不包括区号的电话号码 |
| 橙 | \| | 或操作,匹配区号的多种形式 |
| 绿 | (\d\{3})[- ]\? | 匹配由括号包围的区号及之后的分隔符 |
| 蓝 | \d\{3}- | 匹配没有括号包围的区号 |
由此可见,将区号及其后的连接符作为一个整体捕获为组,这样就可以通过后续的 \? 表达式来匹配0个或1个捕获组,以实现匹配包含区号和不包含区号的多种情况。
捕获组嵌套
以下文本中包含FIRSTNAME LASTNAME格式的姓名信息:
Prepared by Tommas Young Prepared by Tommy Young
使用以下命令,可以将其转换为LASTNAME, FIRSTNAME格式:
:%s/\(Tom\%(mas\|my\)\) \(Young\)/\2, \1/g
Prepared by Young, Tommas Prepared by Young, Tommy
从以上命令可以看到,捕获组是可以嵌套的;\%(\) 指定的组将不会被计数,这可以允许我们使用更多的组,并且查找速度也更快。
捕获组替换
假设需要将以下文本中的单引号替换为双引号:
The string contains a 'quoted' word. The string contains 'two' quoted 'words'. The 'string doesn't make things easy'. The string doesn't contain any quotes, isn't it.
通过以下命令中的嵌套捕获组来完成替换操作:
:%s/\s'\(\('\w\|[^']\)\+\)'/ "\1"/g
The string contains a "quoted" word. The string contains "two" quoted "words". The "string doesn't make things easy". The string doesn't contain any quotes, isn't it.
其中,\s' 用于匹配紧跟在空格之后即单词开头的单引号;\('\w\|[^']\) 则将非开头的单引号视为单词的一部分,以防止其被替换位双引号。