
可以将字典(Dictionary),理解为存储了关于键-值的成对的二元数组。以下将演示在脚本中利用字典数据结构的实例。
删除重复行
在文本排序(sort)章节中,使用以下Vim内置的排序命令,可以去除文件中的重复行,同时原始行的顺序也将随之改变。对于重复的多行,将仅仅保留第一行,而其它的行将被删除。
:%sort u创建自定义函数
以下将自定义Uniq()函数,利用字典数据结构来去除重复行,同时保留原始的行顺序。
 Source code: Uniq.vim
Source code: Uniq.vim
首先,新建一个空字典"have_already_seen"用于遍历指定区域内的所有行;而不重复的行将被加入到字典"unique_lines"中。
因为字典结构不会存储键为空的项目,所以在循环语句中,将为每行内容新增前导字符'>',以确保行不为空。
函数将检查行是否已经作为键存在于字典"have_already_seen"中。如果已经存在,就忽略此行;如果不存在,则被加入字典"unique_lines"中。最后,字典"unique_lines"将仅仅包含所有唯一的行,并以原始的顺序排列;而重复的行,则会被删除。
调用自定义函数
将以上代码添加到vimrc配置文件之后,使用以下命令,可以针对整个文件执行函数:
:%call Uniq()也可以创建快捷键,针对指定的行范围(如可视化模式下选中的行)执行函数:
vmap u :call Uniq()<CR>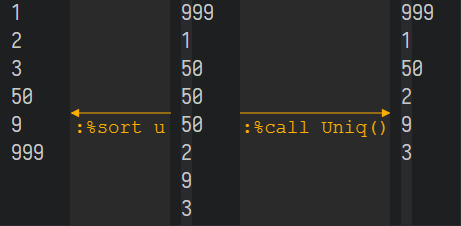



没有评论:
发表评论