zathura是一款高度可定制的简约文档查看器,适用于大多数Linux发行版。zathura是由PWMT社区开发的开源软件,它有以下两大特点:
- 以键盘为中心,使用vim习惯的键位绑定,类似vim的命令行模式,沉浸式的vim操作体验;
- 以文档为中心,极简的用户界面将最大化的屏幕空间留给文档本身,提供更专注的阅读体验。
zathura提供以下主要特性:
- 支持PDF、Djvu、PostScript、Comic Book等多种文件格式;
- 支持书签(bookmark);
- 类似vim的命令行/搜索行/状态栏;
- 使用鼠标双击进行链接跳转;
- 使用鼠标选择文本将自动拷贝至剪贴板;
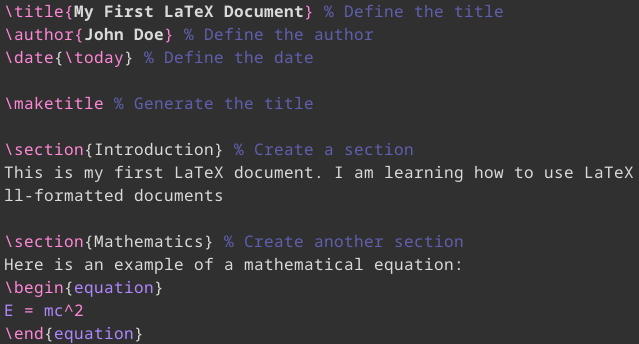
- 支持SyncTeX技术,允许输入和输出同步,便于编辑LaTex文档;
安装
以Debian为例,使用以下命令安装zathura:
$ sudo apt install zathura zathura-pdf-poppler zathura-djvu zathura-ps
针对其它平台的安装,请参阅官方文档。
使用
在操作系统命令行环境下,使用以下命令即可查看文件:
$ zathura filename.pdf
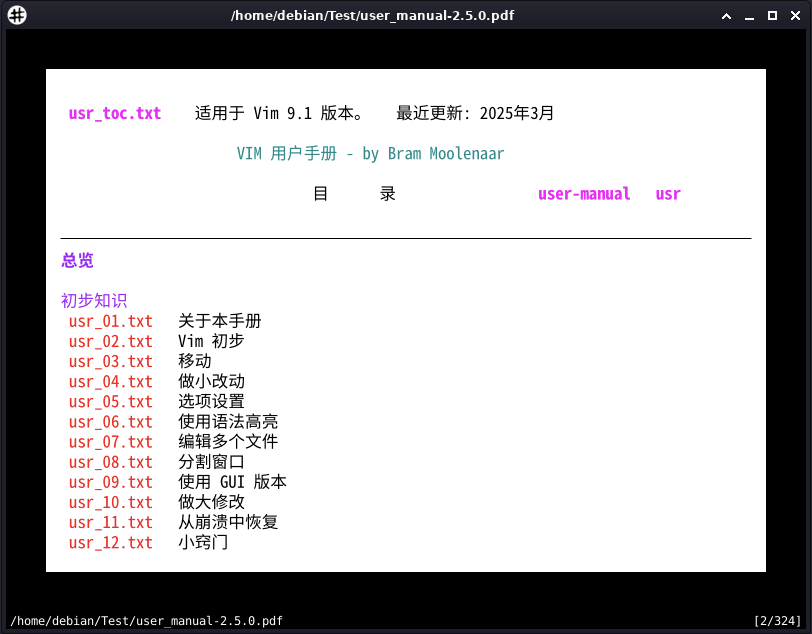
在默认阅读模式下,使用F11键切换至全屏幕模式;使用F5键切换至演示模式;使用Tab键切换至目录模式。
配置
通过编辑~/.config/zathura/zathurarc配置文件,可以自定义系统选项:
# show status bar and vertical scrollbar
set guioptions sv
# allowing to change the colors
set recolor true
set recolor-lightcolor "#000000"
set recolor-darkcolor "#E0E0E0"
set recolor-keephue true
# zoom and scroll step size
set zoom-step 20
set scroll-step 80
# copy selection to system clipboardset
set selection-clipboard clipboard
# enable incremental search
set incremental-search true
# shortcut - zoom
map <C-i> zoom in
map <C-o> zoom out更多配置选项,请参阅官方文档。
快捷键
| Document Navigation | 文档导航 |
| J | 向下移动一行 Move the document display window one line down. |
| K | 向上移动一行 Move the document display window one line up. |
| L | 向右移动一列 Move the document display window one column to the right. |
| H | 向左移动一列 Move the document display window one column to the left. |
| Ctrl + D | 向下移动半页 Move the document display window half a page down. |
| Ctrl + U | 向上移动半页 Move the document display window half a page up. |
| Ctrl + Y | 向右移动半页 Move the document display window half a page to the right. |
| Ctrl + T | 向左移动半页 Move the document display window half a page to the left. |
| Ctrl + B | 向下移动一页 Move the document display window a full page down. |
| Ctrl + F | 向上移动一页 Move the document display window a full page up. |
| Y | 向右移动一页 Move the document display window a full page to the right. |
| T | 向左移动一页 Move the document display window a full page to the left. |
| GG | 移动到第一页 Go to the first page of the current document. |
| Shift + G | 移动到最后一页 Go to the last page of the current document. |
| 5, then Shift + G | 移动到第5页 Go to the fifth page of the current document. |
| Shift + H | 移动到当前页首 Go to the top of the currently selected page. |
| Shift + L | 移动到当前页尾 Go to the bottom of the currently selected page. |
| / | 向前搜索 Open forward search prompt. |
| ? | 向后搜索 Open reverse search prompt. |
| N | 移动到下一匹配处 Go to the next occurrence of the current search term. |
| Shift + N | 移动到上一匹配处 Go back to the previous occurrence of the current search term. |
| Interface Navigation | 界面导航 |
| A | 适合窗口高度 Fit the height of the current page to the display window. |
| S | 适合窗口宽度 Fit the width of the current page to the display window. |
| R | 顺时针旋转90度 Rotate the current document by 90 degrees clockwise. |
| Ctrl + N | 显示/隐藏 状态栏 Toggle status bar. |
| + | 放大 Zoom in |
| - | 缩小 Zoom out |
| = | 恢复缩放比例 Revert the zoom level of the document at the currently selected page. |
| 60 + = | 缩放至指定比例 Set the current zoom level of the document to 60%. |
| Ctrl + R | 反转显示颜色 Invert the colors. |
| Shift + R | 重画屏幕 Refresh and redraw. |
| F5 | 演示模式 presentation mode. |
| F11 | 全屏幕模式 fullscreen mode. |
| Q | 退出/结束当前进程 Terminate the current Zathura session. |
| Linking and Indexing | 链接和目录 |
| Shift + F | 高亮显示链接 Show all link hints. |
| F | 跳转到指定链接 Load a link hint’s page to the document viewer. |
| C | 复制链接地址 Copy a link hint’s page to the system clipboard. |
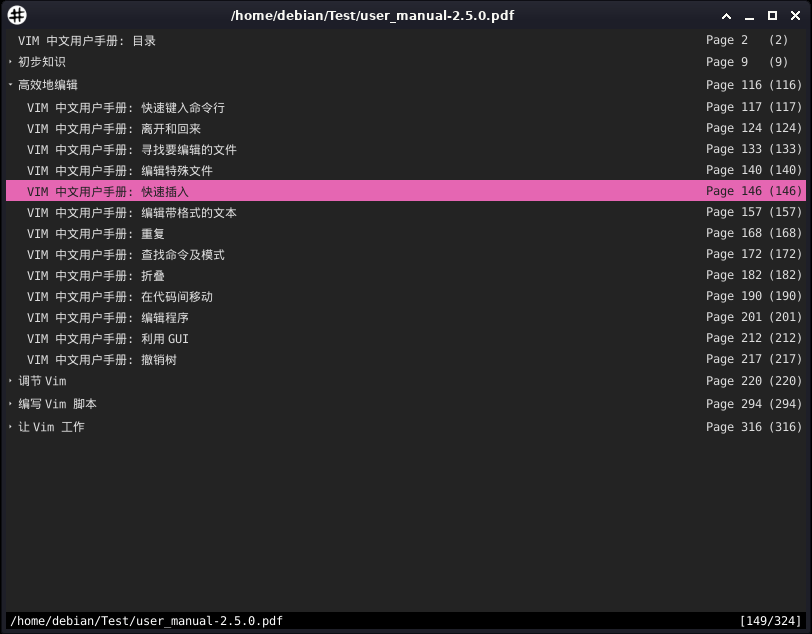
| Tab | 进入目录模式 Display the document’s content index. |
| J | 下一目录项 Scroll one item down in the document’s content index. |
| K | 上一目录项 Scroll one item up in the document’s content index. |
| L | 展开当前目录 Display the current index item’s subitems. |
| H | 折叠当前目录 Hide the current index item’s subitems. |
| Shift + L | 展开所有目录 Display all the subitems in the document’s content index. |
| Shift + H | 折叠所有目录 Hide all the subitems in the document’s content index. |
| Enter | 跳转到目录指引的页 Load the page of the currently selected index entry. |
| Presentation Mode | 演示模式 |
| Space | 下一页 Go to the next document slide. |
| Shift + Space | 上一页 Go back to the previous document slide. |
| F5 | 退出演示模式 Go back to the default Zathura mode. |
| Fullscreen Mode | 全屏幕模式 |
| Shift + J | 下一页 Move the document display window a full page down. |
| Shift + K | 上一页 Move the document display window a full page up. |
| ZI | 放大 Zoom in |
| ZO | 缩小 Zoom out |
| Z0 | 恢复缩放 Reset the current zoom level. |
| 60 + = | 缩放至指定比例 Set the zoom level of the document to 60%. |
| F11 | 退出全屏幕模式 Go back to the default Zathura mode. |
| Command Mode | 命令模式 |
| : | 进入命令行 Open Zathura’s command prompt. |
| :close | 关闭当前文档 Exit the current document without exiting Zathura. |
| :open {filename} | 打开指定文档 Open a new document on the current Zathura window. |
| :blist | 列示书签 List all the available bookmarks for the current session. |
| :bmark {name} | 新增书签 Add the current page to the session’s bookmark index. |
| :bjump {name} | 跳转至指定书签 Jump to a bookmark. |
| :bdelete {name} | 删除书签 Delete bookmark |
| :exec | 执行外部命令 Run an external shell command on the current document. |
| :info | 显示文档信息 Print the document’s internal properties. |
| 打印文档 Send the current document to the machine’s print spool. |